


Will AI replace product managers?
Yes, AI will replace product managers in 3-4 years. What? Why? How? A research-backed analysis.

Claire Vo delivered a haunting talk at a recent Lenny’s Friends summit about the impending death of the product management.
From her perspective, traditional PM’s are going to be soon replaced with AI Generalists. Generalist is a single person responsible for the whole triad - product, design and engineering. It is the owner who sets the strategy and the prompts for the AI agents to execute.
This idea is now knew and talks about AGI explosion that is going to soon take over various creative jobs have been around for a while.
Of course, as a co-founder of ChatPRD, she has a vested interest in this idea. Nevertheless, the concept of generalists resonated with me quite a bit.
In the past few weeks I’ve been tinkering with an AI image generation pet project (I’ll disclose more details on that later). The service has the whole shebang - the modern responsive web-UI, the Flash/python backend, the deployed AI model (stable diffusion).
The catch is - I didn’t design a single component or write a line of code. The entire stack was built entirely with the ChatGPT o1-preview. It took about two days to complete. Two days. Ten years ago, a project of this scope would have taken approximately 4–6 months and required 3–5 people to execute. Unbelievable.
 | Video gifs by quotes | 7e0f218c | 紗")
Impressed by all of this, I decided to dig deeper and look at the actual research data. I’ve spend a few weekends buried in the Cornell University online archive looking for answers in dozens of studies.
How feasible it is for an AI to replace product managers? When will it happen? How will the job look like? Ultimately, what product managers need to be prepared for?
Spoiler - it is feasible and it’s going to happen sooner than you might think. Call me a techno optimist, but research is heavily pointing into that direction.
Let’s dive in and be ready for some technical jargon.
Today’s article
Evolution of LLMs. The exponential performance growth and it’s limits. Evaluation of LLMs model performance.
New LLM frontiers. Recent breakthrough findings that get us dangerously close to AGI.
What will happen to product managers. Can PM skills be replaced with AI? How will the role change in 3-5 years? How will companies change in the same timespan?
+ TL;DR version of the article for people on the go.

📝 Word count: 2683 words
⏱️ Reading time: ~21 minutes
📈 The evolution of LLMs
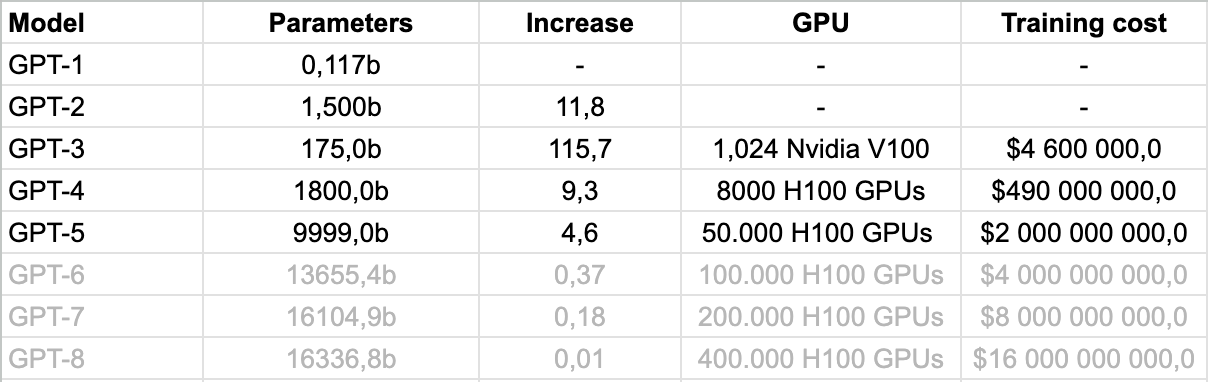
The entire Large Language Model (LLM) training is based a simple empirically proven principle: as the amount of training data increases, the quality of the model’s output improves.
We’ve seen this trend over time with a series of GPT-model launches.
GPT-1 was released in June 2018 with just 117m parameters. GPT-2 came in next year with 1.5b. However, the real breakthrough happened with GPT-3, which had a dramatic x116 more parameters under the hood.
After going into a strategic partnership with Microsoft, getting $1b of funding and access to dedicated GPUs, OpenAI has released a 1.8 trillion parameter GPT-4 model. Training the model took 3 months and came at a staggering cost of $490m. That’s the point where talks about AGI have become specifically heated.
However, when you look closely at the tempo of the parameters increase, it has dramatically slowed down from x116 to just x9 while the cost of training went up x4. According to existing leaks, it is rumored that GPT-5 training did cost ~$2b.
In a recent Lex Fridman interview Dario Amodei (Anthropic founder) mentioned that there’s a VC appetite to fund LLM training of up to $10 billion.
I’d argue that’s exactly the plateau where further investments will reach diminishing returns as you can see on the graph below. My guesstimate is that it’s going to happen around 2027-2028 with GPT-7 release.

The same idea is supported by another paper on “zero-shot” inferences. Researchers evaluated a range of text-to-image models (such as DALL·E, OpenJourney, Stable Diffusion, etc.) to assess their ability to make generalized inferences about concepts they were not trained on.
All of the models failed spectacularly. They couldn’t accurately identify “long-tail” concepts that were rare or absent from the training data. For example, if an image depicts an African Baobab tree but the training dataset never included one, the model would start hallucinating and making errors.
This means that improving performance can only be achieved through exponential growth in training data, which implies increased GPU usage and higher electricity costs.
Ultimately, the current transformer architecture has clear limitations.
🧐 The evaluation of LLMs
OpenAI has been continuously publishing papers, assessing the performance of their models using existing tests (GMAT, GRE, Leetcode, SAT e.t.c.).
I personally find it not fully representative. Why?
According to the recently published paper “On the Planning Abilities of OpenAI models”, all existing models (including the o1-preview) fall short on feasibility, optimality and generalization.

In simple terms, this means that the models struggle to develop feasible plans based on a variety of existing rules, constraints, and dependencies. They have difficulty finding the most optimal solutions. More importantly, they can hardly generalize by transferring logical knowledge from one field to another with different semantics.
Let me illustrate this with an example
For instance, you need to develop a product strategy that will consider existing company process requirements, budget contraints and horizontal team dependencies.
There’s only a ~20% chance that GPT-4 will do a good job at it and a ~50% chance for o1-preview. With the probability that is almost a flip of a coin, the most advanced LLM model will lose some of your requirements or hallucinate new ones. That’s not very inspiring, is it?
When you look at tests like GMAT or GRE each task has a very limited context. Answering an optionality test questions has far less complexity when compared to dealing with multi-dimensional problems like product strategy planning.
It’s not really that surprising.
According to another recent paper published by a research team at Apple, most advanced LLMs are nothing more than just pattern-detection mechanisms.
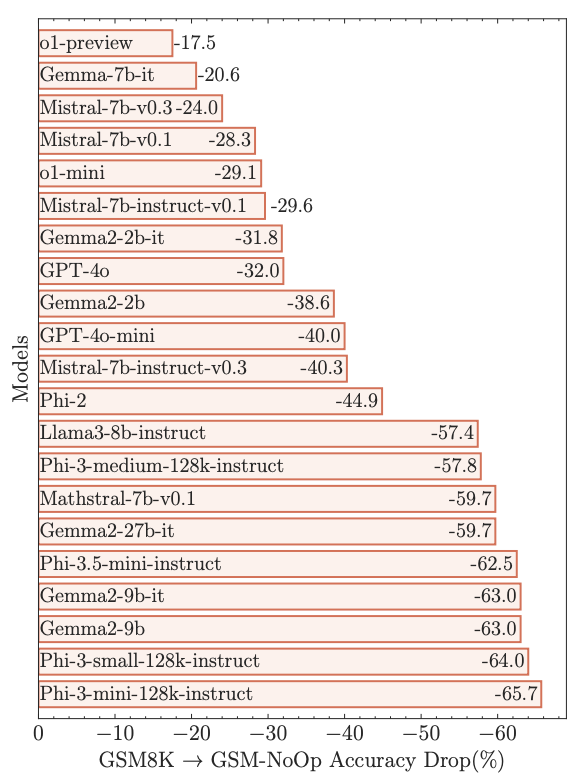
When a team of researchers have slightly modified the task (they called this GSM-NoOp) by adding irrelevant data to the prompt, the model accuracy dropped dramatically.
Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks double the number of kiwis he did on Friday, but five of them were a bit smaller than average (Irrelevant data). How many kiwis does Oliver have?
According to the paper, all of the reviewed models started subtracting those five smaller kiwis from the total amount.
Surprisingly enough, when I tried this on o1-mini just a few days ago - the result was correct (assuming OpenAI had done some fine-tuning there). Claude, however, fails gloriously here.
Ultimately, considering the growth in parameters and training data, my guess is that the maximum threshold for existing LLMs on feasibility will be around ~65% and generalization ~60%.
🚀 New LLM frontiers
Despite the limits of the traditional transformer models there’s hope.
A recent paper from Google DeepMind found that letting AI systems spend more time thinking (aka “compute time”) works better than giving them more data.
In fact, such systems required x4 less computing power and in some instances performed better than models with x14 bigger dataset.
This was achieved by adding a verifier model or iterative step-by-step refinement of an answer. You can already see this in action in the o1-preview chain of thought thinking.
This puts a totally new spin on LLMs.
In fact, o1-preview performed 2.25 times better than GPT-4, despite having the same number of training parameters.
This is a game-changer. Imagine having a GPT-7 model with 16.1 trillion parameters, integrated with a verifier and a chain-of-thought refinement process.

Additionally, let it classify questions based on their complexity before engaging the model. Less complex questions can be answered more simply, requiring very little computational resources.
In a recent study, researchers evaluated the impact of test-time training (TTT) on a model’s reasoning abilities. Test-time training allows the model to adjust itself for a specific task without altering its original weights.
In simple terms, the model approaches a problem (similar to solving a puzzle), determines the best strategy (e.g., sorting puzzle pieces by color), and makes specific adjustments to solve the problem more efficiently (e.g., developing a new sorting method). After the task is completed, the adjustments made by the LoRA (Low-Rank Adaptation) filters are removed, leaving the original model unchanged.
Using this approach, even a relatively small model with 8 billion parameters achieved a 53% generalization accuracy. When combined with other established techniques, the accuracy increased to 61.9%. Sorry to break it for you guys, but this performance is akin to a human-level generalization.